






As organizations transition to AI-first strategies, the data pipeline has become the most critical piece of the puzzle. It is the bridge that moves raw information from its source to
As organizations transition to AI-first strategies, the data pipeline has become the most critical piece of the puzzle. It is the bridge that moves raw information from its source to the analytics and AI models that drive value.
However, many companies find that as their data grows, so do their cloud bills. Poorly architected pipelines often lead to "compute bloat"—where you pay for massive processing power that delivers diminishing returns. Building a pipeline that scales sustainably requires a shift from "maximum capacity" thinking to "dynamic efficiency."
Here is how to build a world-class data architecture while maintaining strict financial discipline, supported by the experts at Addepto.
Strategy First: Prioritize Signal Over Noise
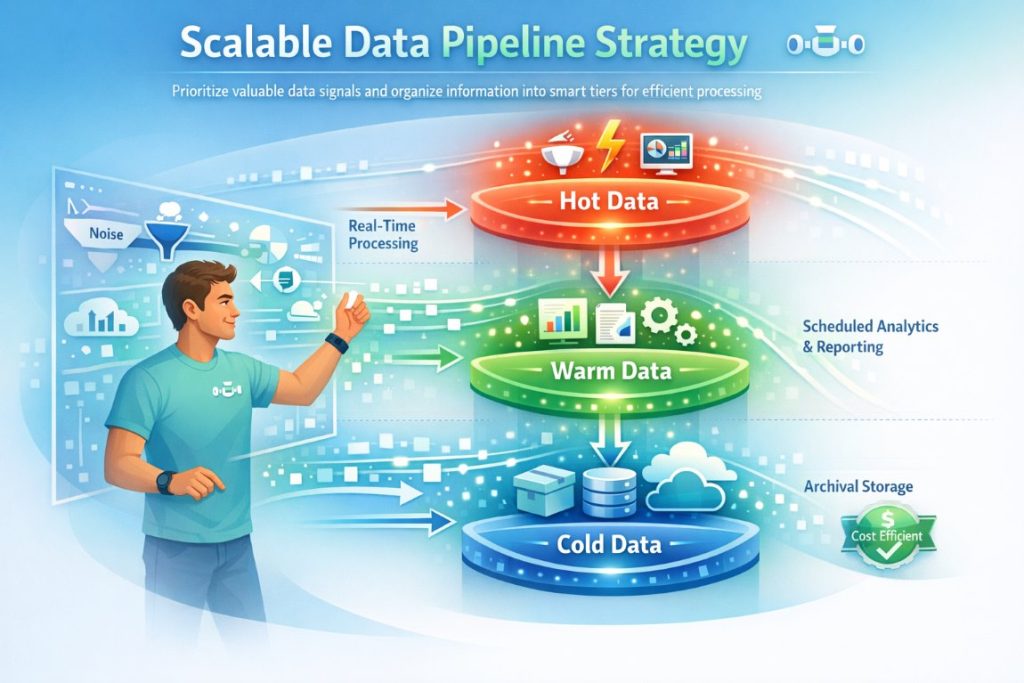
The most expensive data is the data you process but never use. Before investing in infrastructure, you must define your analytical goals.
Many organizations fall into the "collect everything" trap. A scalable pipeline starts with classification:
- Hot Data: Critical operational metrics requiring real-time stream processing.
- Warm Data: Daily or hourly business intelligence reports.
- Cold Data: Historical logs that can be archived in low-cost storage.
By aligning your pipeline with these tiers, you avoid the cost of high-performance processing for low-priority data.
Design for Modular Scalability
A "monolithic" pipeline—where ingestion, transformation, and storage are tightly coupled—is a recipe for budget disaster. If one part of the system needs more power, you end up overpaying to scale the entire stack.
Modern architectures should be decoupled. This allows you to scale individual components based on actual demand. Addepto specializes in these modular data engineering services (https://addepto.com/data-engineering-services/), ensuring that your architecture is flexible enough to grow without a total redesign.
Serverless and Event-Driven Processing

Why pay for a server to sit idle at 2:00 AM? One of the best ways to control costs is to move toward event-driven or "serverless" processing.
- Traditional: Servers run 24/7, regardless of data volume.
- Modern: The pipeline "wakes up" only when new data arrives, processes it, and shuts back down.
This ensures you are only billed for the exact compute time you use, effectively tethering your costs to your actual business activity.
The ROI of Early Data Quality
One of the biggest "hidden" costs in data engineering is re-processing. When poor-quality data enters the pipeline, it causes errors downstream that require manual fixes and expensive re-runs of transformation jobs.
The Golden Rule: It is 10x cheaper to validate data at the point of ingestion than it is to fix it in the data warehouse.
By integrating automated validation and cleaning steps early, you ensure the pipeline runs lean.
Automated Monitoring and "FinOps"

You cannot optimize what you do not measure. As pipelines grow, manual oversight becomes impossible. Automated monitoring tools help track:
- Throughput: How much data is moving?
- Latency: Is the data reaching decision-makers fast enough?
- Cost-per-Job: Which queries or processes are eating the most budget?
AI-driven optimization can then identify underutilized resources or inefficient code, allowing your engineers to fine-tune the system before the monthly cloud bill arrives.
Conclusion: Building for the Future
A scalable data pipeline is the foundation for everything from predictive analytics to generative AI applications. As organizations move toward AI-first strategies, choosing the right development partners becomes just as important as building the right infrastructure. Exploring leading AI application development companies can help businesses accelerate their AI initiatives while ensuring their data architecture supports long-term innovation.
Respond to this article with emojis